kafka 简介
Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统, 使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点,较之传统的消息中 间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容 错的特性,非常适合大规模消息处理应用程序。
kafka系统架构图
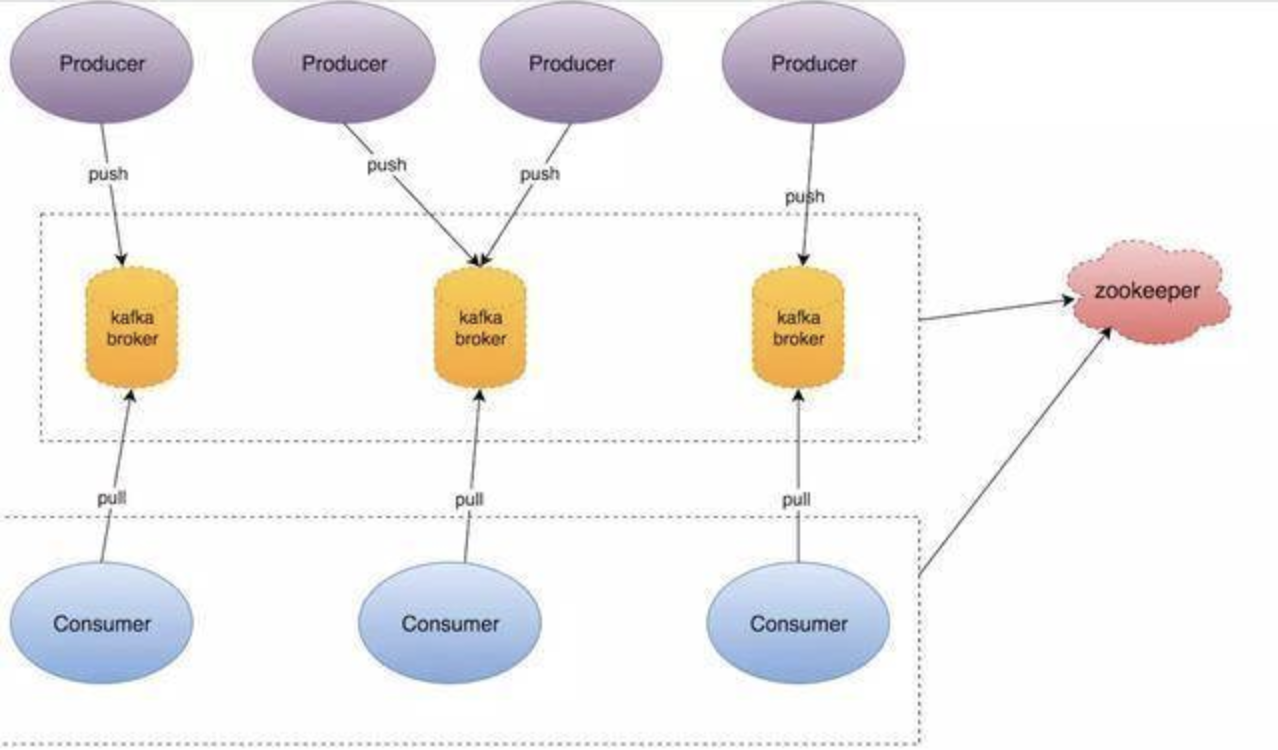
如上图,一个kafka架构包括若干个Producer(服务器日志、业务数据、web前端产生的page view等),若干个Broker(kafka支持水平扩展,一般broker数量越多集群的吞吐量越大),若干个consumer group,一个Zookeeper集群(kafka通过Zookeeper管理集群配置、选举leader、consumer group发生变化时进行rebalance)。
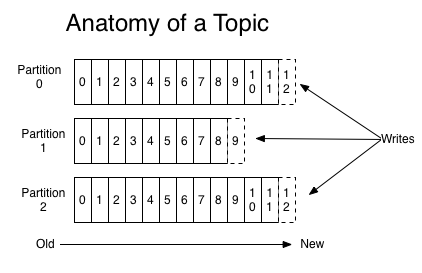
主题和分区
在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。主题就好比数据库的表,或者文件系统里的文件夹。主题可以被分为若干个分区(Partition)。消息以追加的方式写入分区,然后以先入先出的顺序读取。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。 kafka通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说, 一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。
生产者和消费者
kafka 的客户端被分为两种基本类型 : 生产者(Producer)和消费者(consumer), 除此之外还有其他高级API.
生产者创建消息,消费者读取消息.
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息,而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。我们把生产者和消费者统称为客户端(Clients)。
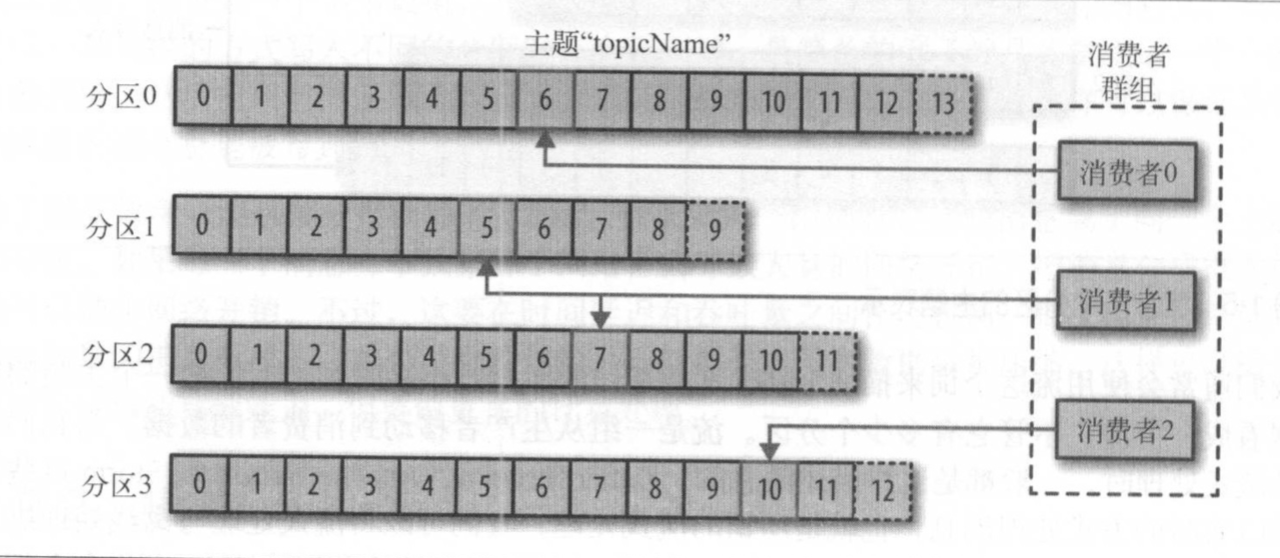
消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。 偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时, Kafka 会把它添加到消息里。
在给定的分区里,每个消息的偏移量都是唯 一 的。消费者把每个分区最后读取的消息偏移量保存在 Zookeeper或 Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
消费者是消费者群组中的一部分,群组保证每个分区只能被一个消费者使用
通过这种方式,消费者可以消费包含大量消息的主题。而且,如果一个消费者失效,群组里的其他消费者可以接管失效消费者的工作
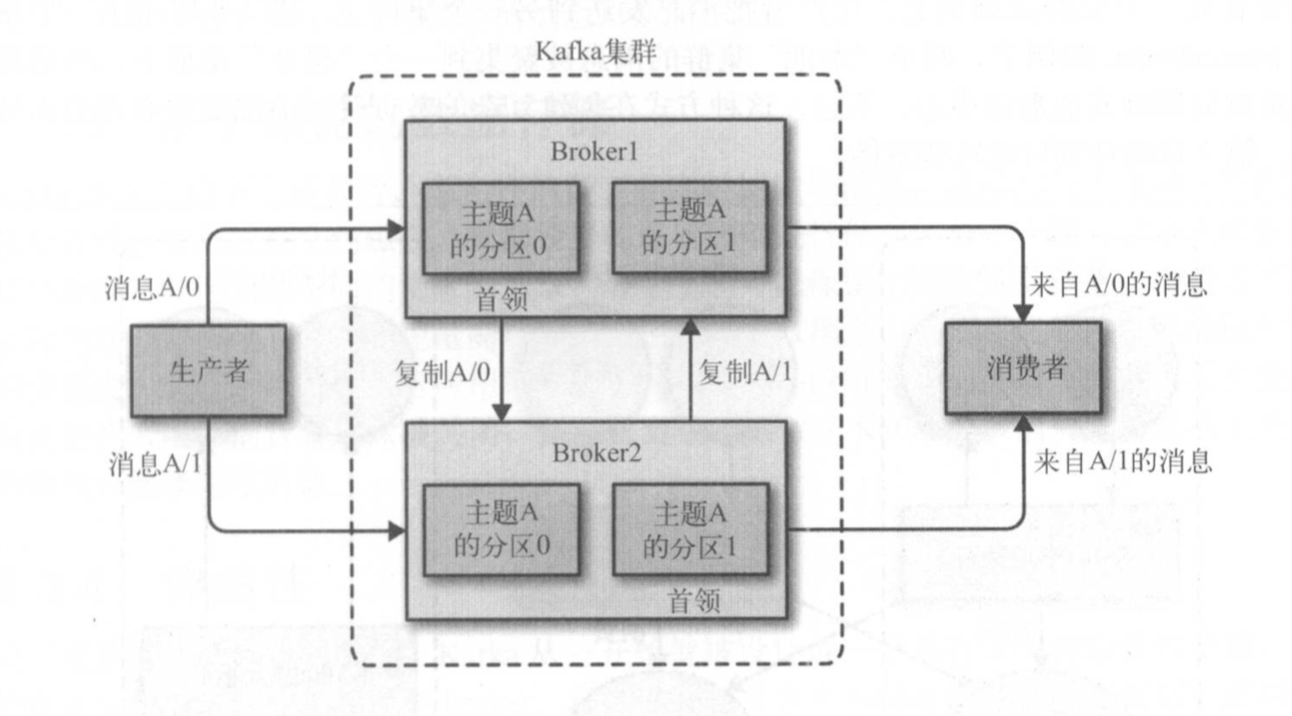
broker和集群
一个独立的 Kafka服务器被称为 broker。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。 broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
broker是集群的组成部分。每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
保留消息(在一定期限内)是 Kafka的一个重要特性。 Kafka broker默认的消息保留策略是这样的: 要么保留一段时间(比如7天),要么保留到消息达到一定大小的字节数(比如1GB)。当消息数量达到这些上限时,旧消息就会过期并被删除,所以在任何时刻, 可用消息的总量都不会超过配置参数所指定的大小。
kafka高吞吐率的实现
Kafka 与其它 MQ 相比,其最大的特点就是高吞吐率。为了增加存储能力,Kafka 将所有的消息都写入到了低速大容的硬盘。按理说,这将导致性能损失,但实际上,kafka 仍可保持超高的吞吐率,性能并未受到影响。其主要采用了如下的方式实现了高吞吐率。
顺序读写: Kafka将消息写入到了分区partition中,而分区中消息是顺序读写的。顺序
读写要远快于随机读写。
零拷贝: 生产者、消费者对于kafka中消息的操作是采用零拷贝实现的, 不需要经过ALU(算术逻辑单元)
批量发送: Kafka允许使用批量消息发送模式, 可以按长度或者时间设置阈值
消息压缩: Kafka支持对消息集合进行压缩。