生产者消息分区机制
为什么分区
其实分区的作用就是提供负载均衡的能力,或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)。不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。
分区策略
轮询策略
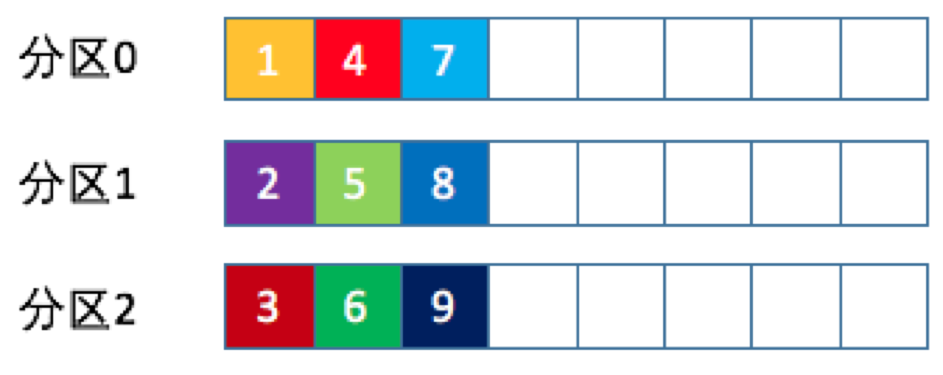
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
随机策略
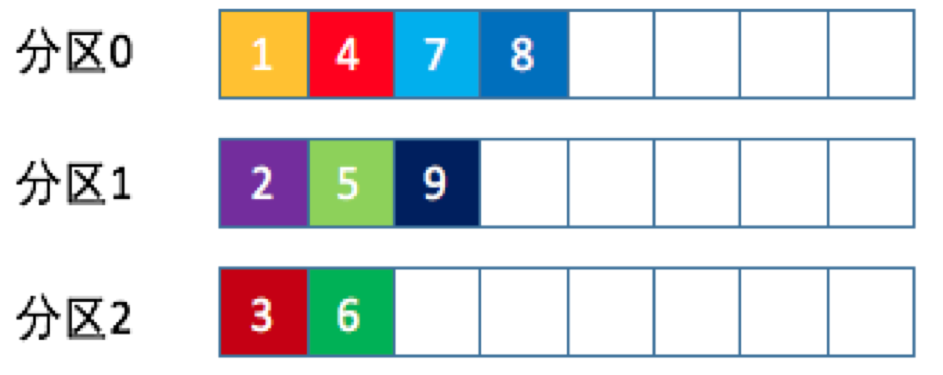
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
按消息键保序策略
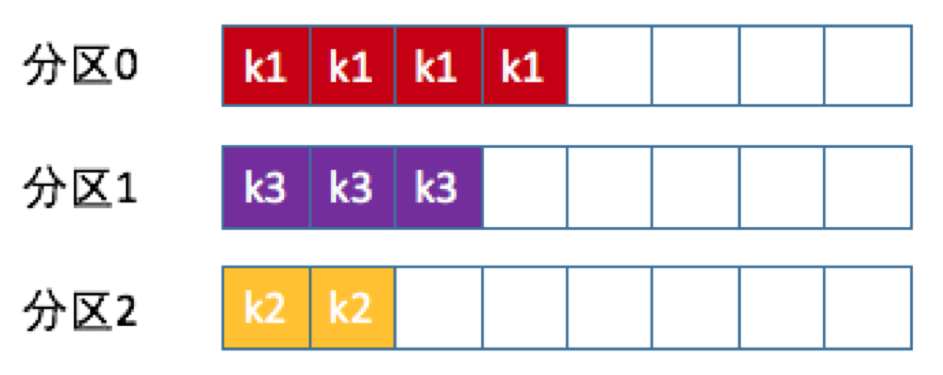
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,如下图所示。
Kafka压缩算法
说起压缩,我相信你一定不会感到陌生。它秉承了用时间去换空间的经典 trade-off 思想,具体来说就是用 CPU 时间去换磁盘空间或网络 I/O 传输量,希望以较小的 CPU 开销带来更少的磁盘占用或更少的网络 I/O 传输。在 Kafka 中,压缩也是用来做这件事的。
何时压缩
在 Kafka 中,压缩可能发生在两个地方:生产者端和 Broker 端。
生产者程序中配置 compression.type 参数即表示启用指定类型的压缩算法。比如下面这段程序代码展示了如何构建一个开启 GZIP 的 Producer 对象:
1 |
|
这里比较关键的代码行是 props.put(“compression.type”, “gzip”),它表明该 Producer 的压缩算法使用的是 GZIP。这样 Producer 启动后生产的每个消息集合都是经 GZIP 压缩过的,故而能很好地节省网络传输带宽以及 Kafka Broker 端的磁盘占用。
在生产者端启用压缩是很自然的想法,那为什么我说在 Broker 端也可能进行压缩呢?其实大部分情况下 Broker 从 Producer 端接收到消息后仅仅是原封不动地保存而不会对其进行任何修改,但这里的“大部分情况”也是要满足一定条件的。有两种例外情况就可能让 Broker 重新压缩消息。
情况一:Broker 端指定了和 Producer 端不同的压缩算法。
先看一个例子。想象这样一个对话。Producer 说:“我要使用 GZIP 进行压缩。”
Broker 说:“不好意思,我这边接收的消息必须使用 Snappy 算法进行压缩。”
你看,这种情况下 Broker 接收到 GZIP 压缩消息后,只能解压缩然后使用 Snappy 重新压缩一遍。
如果你翻开 Kafka 官网,你会发现 Broker 端也有一个参数叫 compression.type,和上面那个例子中的同名。但是这个参数的默认值是 producer,这表示 Broker 端会“尊重”Producer 端使用的压缩算法。可一旦你在 Broker 端设置了不同的 compression.type 值,就一定要小心了,因为可能会发生预料之外的压缩 / 解压缩操作,通常表现为 Broker 端 CPU 使用率飙升。
情况二:Broker 端发生了消息格式转换。所谓的消息格式转换主要是为了兼容老版本的消费者程序。在一个生产环境中,Kafka 集群中同时保存多种版本的消息格式非常常见。为了兼容老版本的格式,Broker 端会对新版本消息执行向老版本格式的转换。这个过程中会涉及消息的解压缩和重新压缩。一般情况下这种消息格式转换对性能是有很大影响的,除了这里的压缩之外,它还让 Kafka 丧失了引以为豪的 Zero Copy 特性。
所以尽量保证消息格式的统一吧,这样不仅可以避免不必要的解压缩 / 重新压缩,对提升其他方面的性能也大有裨益。
何时解压缩?
有压缩必有解压缩!通常来说解压缩发生在消费者程序中,也就是说 Producer 发送压缩消息到 Broker 后,Broker 照单全收并原样保存起来。当 Consumer 程序请求这部分消息时,Broker 依然原样发送出去,当消息到达 Consumer 端后,由 Consumer 自行解压缩还原成之前的消息。
那么现在问题来了,Consumer 怎么知道这些消息是用何种压缩算法压缩的呢?
其实答案就在消息中。Kafka 会将启用了哪种压缩算法封装进消息集合中,这样当 Consumer 读取到消息集合时,它自然就知道了这些消息使用的是哪种压缩算法。
如果用一句话总结一下压缩和解压缩:Producer 端压缩、Broker 端保持、Consumer 端解压缩。